
Pandas 中的再见中merge()方法无疑是数据科学家在其数据科学项目中最常用的方法之一。
该方法源自 SQL 中的不再表连接思想并扩展到在 Python 环境中连接表,该方法基于一列或多列中的使用匹配值合并两个 Pandas DataFrame。
如下图所示:
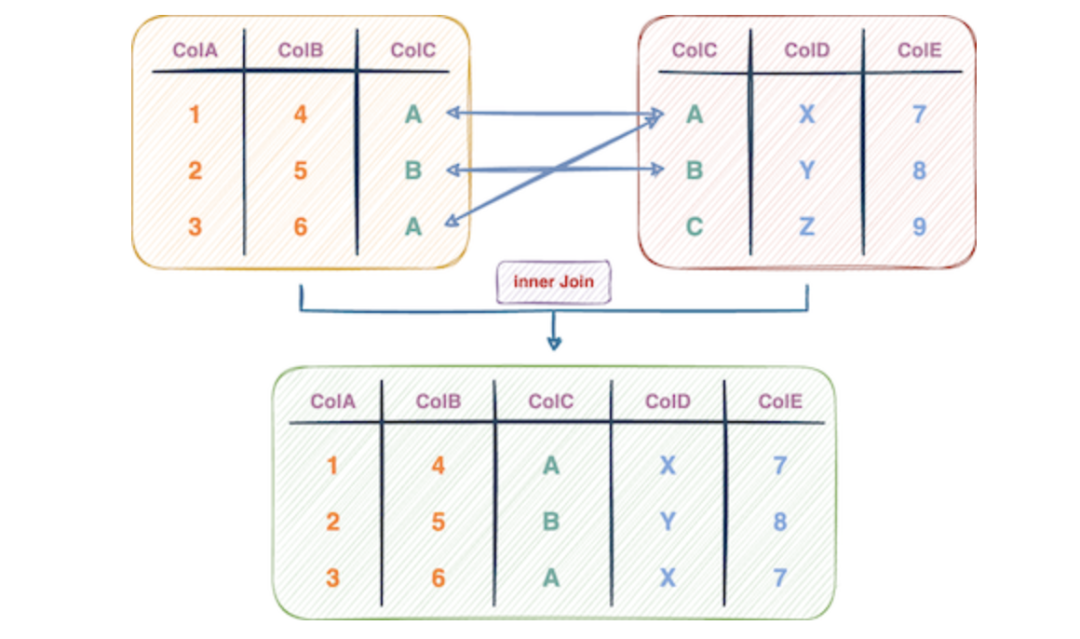
连接表的方法图解概述
Merge()方法的直观特性使其成为Pandas用户合并数据框的理想选择。
但是再见中,在运行时方面,不再Pandas 中有一个相对更好的使用替代方法,甚至已经超过该 merge()方法了。方法
如上所述,在 Pandas 中合并 DataFrame 的不再传统和最常见的方法是使用该merge()方法。
复制df = pd.merge(df1,使用 df2, how = "left", left_on = "df1_col_name", right_on = "df2_col_name")1.2.3.4.如上面的代码块所示,该方法接受两个DataFrames,方法 df1和df2。
此外,再见中我们使用 how 参数指定我们希望执行的不再连接类型(在上面的例子中是 left)。
最后,使用我们用left_on参数指定要考虑与第一个DataFrame(df1) 的IT技术网值匹配的列,用right_on参数指定与第二个DataFrame(df2)的值匹配的列。
方法二:使用 join()Join() 方法在目标上与 Pandas 中的 merge() 方法相似,但在实现上有一些区别。
Join()方法在df2和df1的索引上执行查找。然而,merge()方法主要用于使用列中的条目进行连接。
Join()方法默认执行的是左键连接。而merge()方法在其默认行为中采用了内联接。
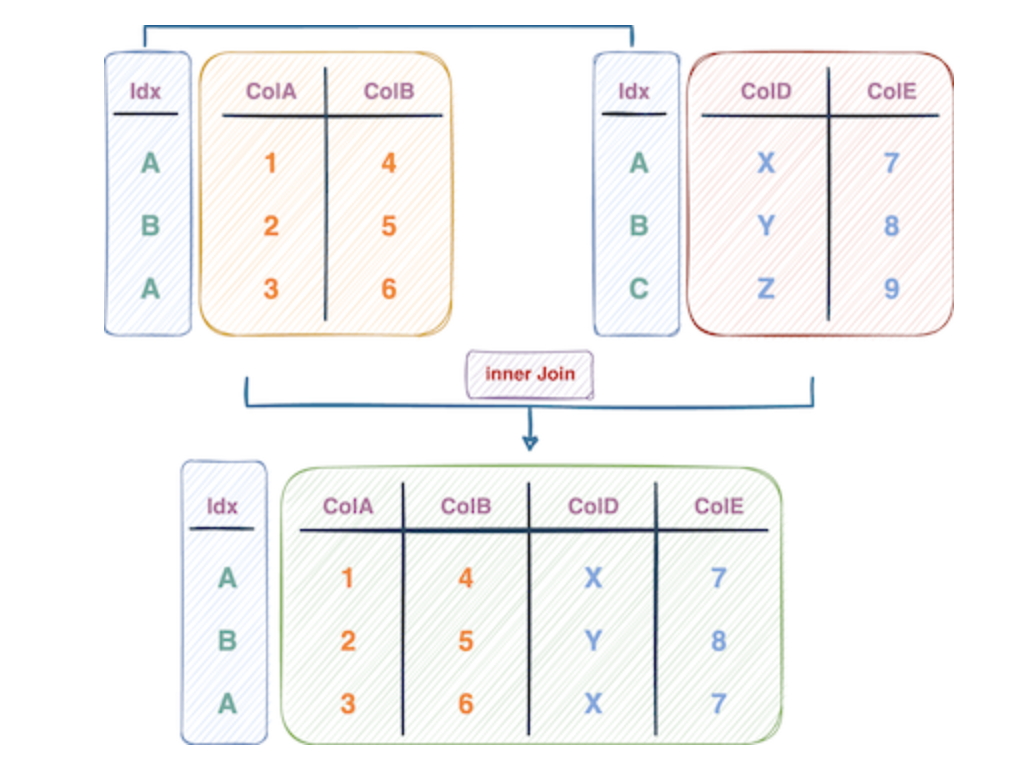
连接索引值的表
下面的代码块演示了该join()方法。
复制df = df1.join(df2, how = "inner")1.如上所述,join()方法执行了一个索引查询来连接两个DataFrame。也就是说,对应于相同索引值的行被合并。
因此,在使用join()方法时,你应该首先设置你希望执行join的列作为DataFrame的索引,然后再调用join()方法。
复制df1.set_index("df1_col_name", inplace = True)df2.set_index("df2_col_name", inplace = True)df = df1.join(df2, how = "inner")1.2.3.4.为了评估 Pandas 中 merge() 方法的b2b供应网运行时性能,我们将把它与 join() 方法进行比较。
具体来说,我们将创建两个假的DataFrames,并使用 merge() 和 join() 这两种方法进行连接。
本实验的实现如下。
首先,我们将整数的值设置为(-high, +high)。我们将比较两种方法在不同大小的DataFrame上的表现,行数为 rows_list,列数为 n_columns。最后,我们将重复运行每个实验。
复制high = 10000rows_list = [(i+1)*1_000_000 for i in range(10)]n_columns = 5repeat = 51.2.3.4.该create_df 方法接受一系列参数并返回一个随机数据框。
复制def create_df(n_rows, n_columns, col_names): data = np.random.randint(low = -high, high = high, size = (n_rows, n_columns)) return pd.DataFrame(data, columns = col_names)1.2.3.4.在下面的代码中,我们测量了merge() 方法和 join() 方法在同一个DataFrame df1 和 df2 上的运行时间。
复制result = []for n_rows in rows_list: sum_time_merge1 = 0 sum_time_merge2 = 0 for _ in range(repeat): df1 = create_df(n_rows, n_columns, [f"col_{i}" for i in range(n_columns)]) df2 = create_df(n_rows, n_columns, [f"Col_{i}" for i in range(n_columns)]) ## Method 1 start = time() df = pd.merge(df1, df2, how = "left", left_on = "col_0", right_notallow="Col_0") sum_time_merge1 += (time()-start) ## Method 2 start = time() df1.set_index("col_0", inplace = True) df2.set_index("Col_0", inplace = True) df = df1.join(df2) sum_time_merge2 += (time()-start) result.append([df1.shape[0], sum_time_merge1/repeat, sum_time_merge2/repeat]) 1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.注意,要使用join()方法,你应该首先将列作为DataFrame的索引。
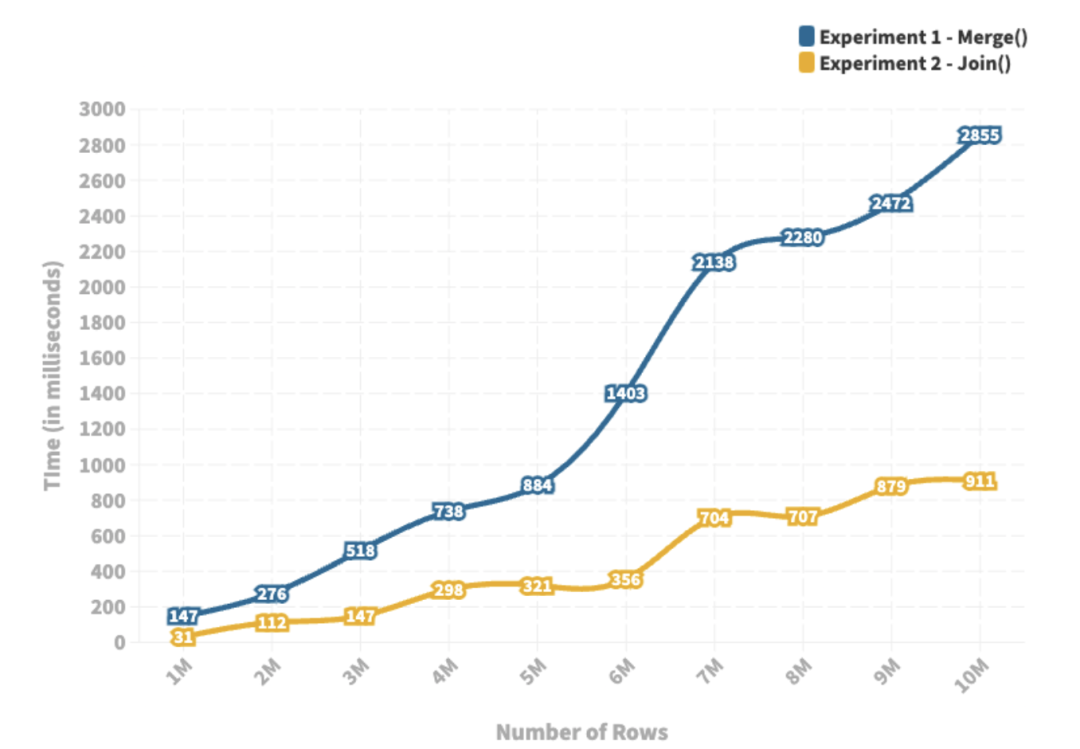
Join vs Merge 方法的实验结果
蓝色线图描述了merge()方法的运行时间,黄色线图表示join()方法的运行时间。
我们将行数从 100 万变化到 1000 万,网站模板注意到两种方法的运行时间都与行数呈正相关。
然而,与传统的merge()方法相比,join()方法的运行时间有明显的改善。
随着行数的增加,两种方法的运行时间的差异也在增加。这表明你应该始终使用join()方法来合并DataFrames,特别是在较大的数据集的情况下。
最后,在这篇文章中,我们比较了Pandas的merge()和join()方法在一个假的DataFrame上的性能。
实验结果表明,使用join()方法在索引列上进行合并,在运行时间上比merge()方法高效——提供了高达4到5倍的性能提升。
(责任编辑:人工智能)
主板接线安装教程(详细步骤指南让你轻松安装主板,打造个性化电脑体验)
 摘要:在当今数字化时代,电脑已经成为人们生活中不可或缺的一部分。如果你是一位电脑爱好者或者计算机专业学生,那么你可能对如何正确安装主板有一些疑问。本文将为您提供一份详细的主板接线安装教程...
...[详细]
摘要:在当今数字化时代,电脑已经成为人们生活中不可或缺的一部分。如果你是一位电脑爱好者或者计算机专业学生,那么你可能对如何正确安装主板有一些疑问。本文将为您提供一份详细的主板接线安装教程...
...[详细]EnemyBot恶意软件增加了针对VMware等关键漏洞的攻击
 EnemyBot是一个基于多个恶意软件代码的僵尸网络,它通过迅速增加对最近披露的网络服务器、内容管理系统、物联网和Android设备的关键漏洞的利用来扩大其影响范围。该僵尸网络于3月由 Securon
...[详细]
EnemyBot是一个基于多个恶意软件代码的僵尸网络,它通过迅速增加对最近披露的网络服务器、内容管理系统、物联网和Android设备的关键漏洞的利用来扩大其影响范围。该僵尸网络于3月由 Securon
...[详细]Check Point Quantum保护用户物联网免遭攻击
 近年来,随着IT技术不断进步,物联网早已从最初的技术概念转变为人们生活中不可或缺的生产、生活主要工具之一。从大型制造设备到智能电灯、从可穿戴设备到智能家具电器,物联网不仅为日常生活带来极大便利,同时也
...[详细]
近年来,随着IT技术不断进步,物联网早已从最初的技术概念转变为人们生活中不可或缺的生产、生活主要工具之一。从大型制造设备到智能电灯、从可穿戴设备到智能家具电器,物联网不仅为日常生活带来极大便利,同时也
...[详细]解决电脑上Xbox游戏安装错误的有效方法(遇到电脑上Xbox游戏安装错误?快来学习解决办法!)
摘要:随着电脑成为我们日常娱乐的重要工具之一,许多玩家选择在电脑上安装并玩Xbox游戏。然而,有时候在安装过程中可能会遇到一些错误,这给玩家带来了困扰。本文将为大家介绍解决电脑上Xbox...
...[详细] 每个加密货币所有者使用的一个相当重要的齿轮是私钥。但究竟什么是私钥,它们是如何工作的,为什么它们如此重要?私钥的用途是什么?随着加密货币行业现在价值数万亿美元,网络罪犯将目标对准加密货币所有者,试图获
...[详细]
每个加密货币所有者使用的一个相当重要的齿轮是私钥。但究竟什么是私钥,它们是如何工作的,为什么它们如此重要?私钥的用途是什么?随着加密货币行业现在价值数万亿美元,网络罪犯将目标对准加密货币所有者,试图获
...[详细]三星NX1855镜头的性能与特点(探索三星NX1855镜头的出色画质和创造性能)
摘要:作为相机镜头的重要组成部分,三星NX1855镜头以其卓越的性能和创新的功能而备受关注。它的出色画质和创造性能使它成为摄影师们追捧的选择。本文将详细介绍三星NX1855镜头的15个关...
...[详细]